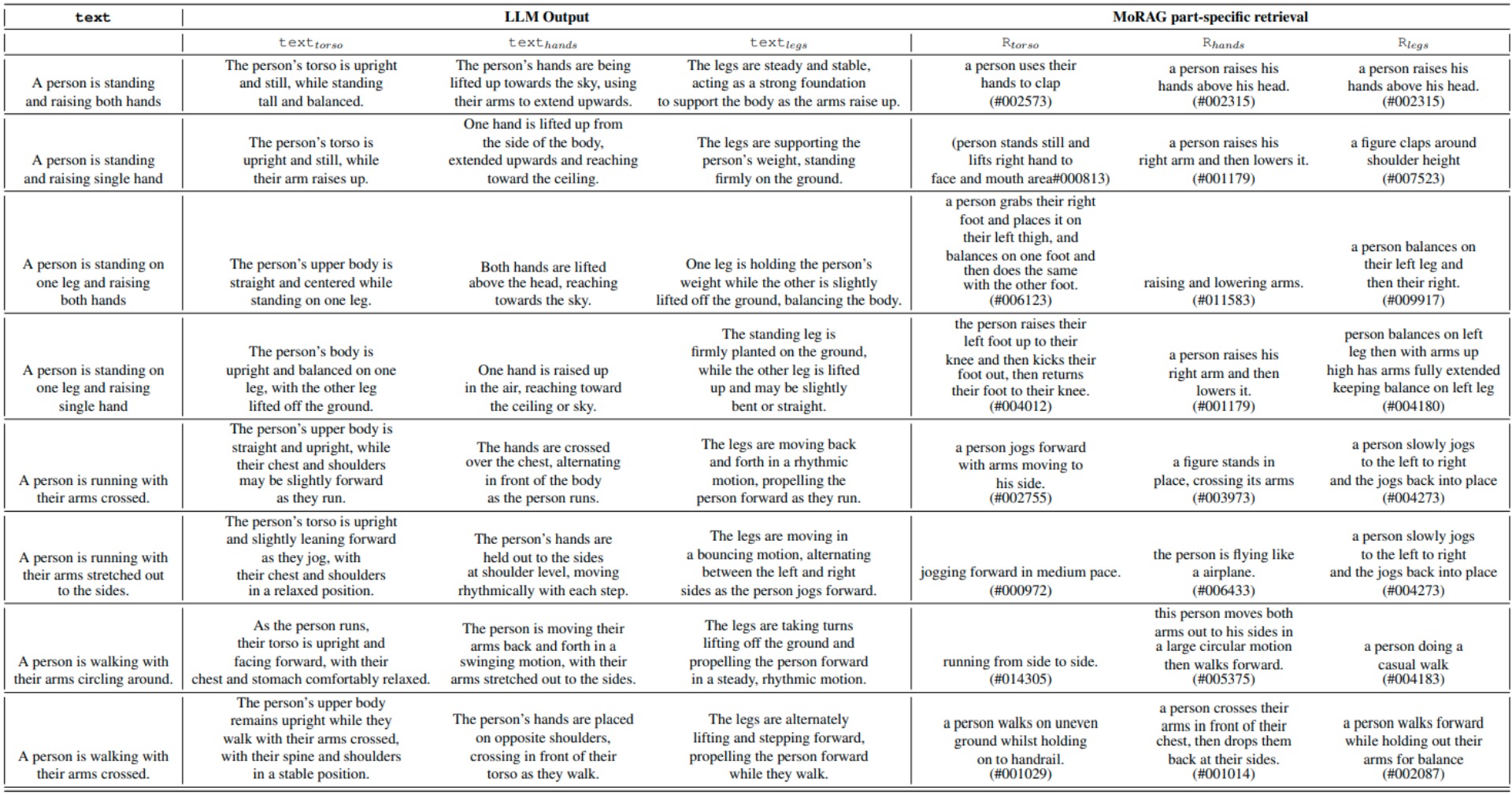
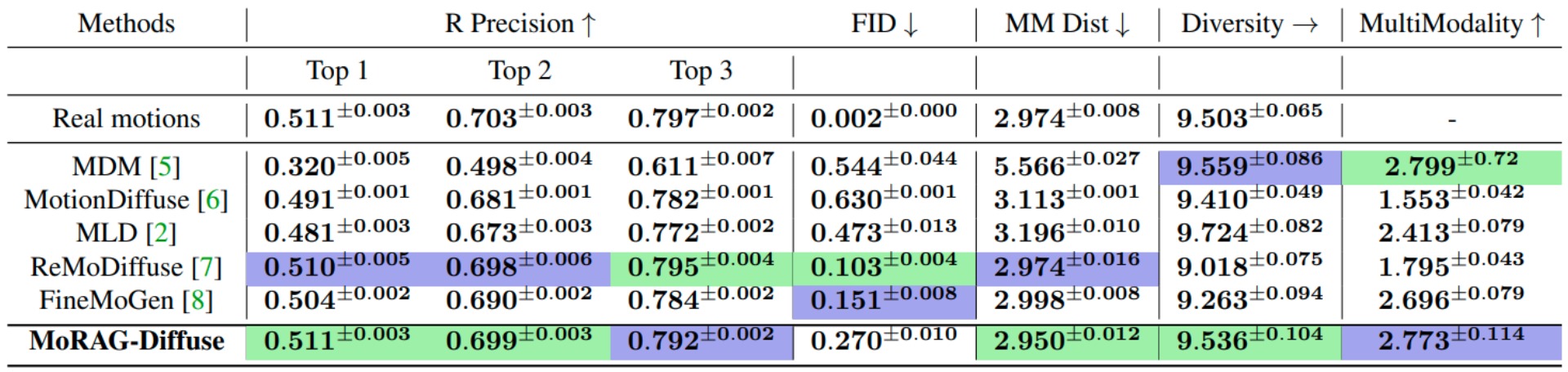
We introduce MoRAG, a novel multi-part fusion based retrieval-augmented generation strategy for text-based human motion generation.
The method enhances motion diffusion models by leveraging additional knowledge obtained through an improved motion retrieval process. By effectively prompting large language models (LLMs), we address spelling errors and rephrasing issues in motion retrieval. Our approach utilizes a multi-part retrieval strategy to improve the generalizability of motion retrieval across the language space. We create diverse samples through the spatial composition of the retrieved motions. Furthermore, by utilizing low-level, part-specific motion information, we can construct motion samples for unseen text descriptions. Our experiments demonstrate that our framework can serve as a plug-and-play module, improving the performance of motion diffusion models.